
在鐵人賽尾聲,Spring AI 還釋出了 1.0.0 M2 版本,在這個版本多了評估( Evaluator )跟節制( Moderation ),在 Structured Output 的部分也多了 Json Schema,這可是 Open AI 八月份才推出的功能
對功能性來說 Spring AI 算是跟得很快,Open AI 的 API 有的功能幾乎都很快的實現在框架上,不過對於一些應用的功能卻十分陽春,例如昨天提的幾個讓搜尋準確度更高的手法,在 LangChain 框架都已有實作方案,Spring AI 的開發人員甚至還要研究 LangChain 框架怎麼做,或許這也是 Java 在資料分析領域落後太久的緣故,微軟發布了 Graph RAG 的論文後,我一直想等 Spring AI 或是有甚麼 Java 神人可以將它移植到 Spring AI 上,很可惜到現在還是沒有,Spring AI 的 GitHub 甚至沒人提出這個 Issue
看著其他參賽者的文章,參考資料可以列出一堆,而 Spring AI 卻只有官方文檔可以參考,除了用 Java 開發 AI 應用的人較少外,Spring AI 這框架也是今年 2 月才釋出,網路上找到的資料甚至一大半都是舊版的寫法(我也算是中文界介紹新版寫法的首發了XD),或許這也是大部分企業尚未引入 AI 的原因,除了怕資料外洩外,企業許多使用 Java 開發的程式也容易跟其他語言整合
即使如此,我仍很看好 Spring AI 未來的發展,一來是 Java 開發人員可以很容易的與 Spring 框架整合,再來是透過 RAG 的方式,企業可將機密資料掌握在自己手裡,這兩點對企業導入 AI 格外重要
感謝 Aico 的開發者傾囊相授,Graph RAG 最重要的就是將資料拆分成Entities 與 Relations,這部分只需讓 LLM 處理,我們只需給輸出的結構就能自己分析文章產生 Entities 與 Relations,以前要花人工處理的內容現在一瞬間就完成,下面就是 R 大提供的方法
## OpenAI Function Schema
const functionSchema = {
name: "extract_entities_and_relations",
description: "從給定的文本中提取實體和關係",
parameters: {
type: "object",
properties: {
entities: {
type: "array",
items: {
type: "object",
properties: {
name: { type: "string" },
type: { type: "string" }
},
required: ["name", "type"]
},
description: "文本中提到實體陣列,每個實體包含名稱和類型,名稱愈細愈好,不用硬填範例資料"
},
relations: {
type: "array",
items: {
type: "object",
properties: {
from: { type: "string" },
to: { type: "string" },
type: { type: "string" }
},
required: ["from", "to", "type"]
},
description: "實體之間的關係陣列,每個陣列包含'from'實體、'to'實體和關聯類型,不用硬填範例資料"
}
},
required: ["entities", "relations"]
}
};
## System Prompt
const instruction = [
"你是一位 Neo4j 圖據庫專家。你的任是分析給定的文本,提取適合 Neo4j 圖結構的實體(作為節)和關係。請循以下指南:",
"1. 識別主要實體作為節點,包括人、地點、物品、概念等。",
"2. 確定體之間的關係,這些將成 Neo4j 中的邊。",
"3. 為節點分配適當的標籤(例如 :Person, :Place, :Organization)。",
"4. 為關係指定具體的類型(例如 :WORKS_AT, :LOCATED_IN)。",
"例如,對於文本「小明在北京的清華大學學習計算機科學」,應提取",
"節點:",
"(:Person {name: '小明'})",
"(:City {name: '北京'})",
"(:University {name: '清華大學'})",
"(:Subject {name: '計算機科學'})",
"關係:",
"(:Person {name: '小明'})-[:STUDIES_AT]->(:University {name: '清華大學'})",
"(:Person {name: '小明'})-[:STUDIES]->(:Subject {name: '計算機科學'})",
"(:University {name: '清華大學'})-[:LOCATED_IN]->(:City {name: '京'})",
"請確保你輸出可以直接用於創建 Neo4j 圖數據庫的 Cypher 查詢。",
].join("\n");
—來自Aico發佈於Aico - 專為夢境解讀設計的 AI https://vocus.cc/article/66c68d1efd89780001106a58
在 Spring AI 上可使用 BeanOutputConverter 搭配上面的 Json Schema 將 Json 轉為物件,之後再透過 Spring Data Neo4j 就能輕易的維護知識圖譜
ETL 的流程則會調整如下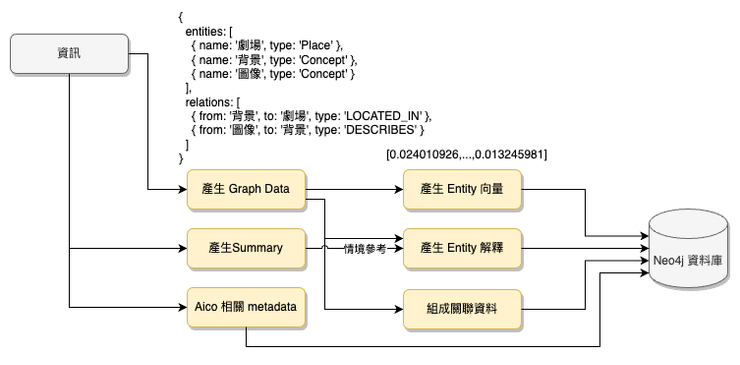
最後查詢的過程則是下圖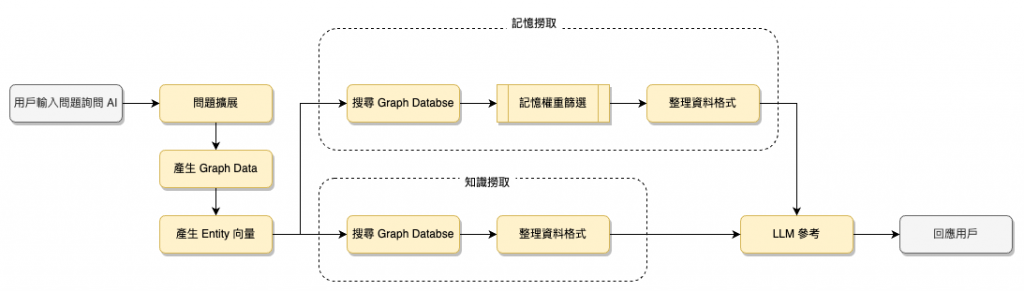
以上內容皆取自 Aico - 專為夢境解讀設計的 AI https://vocus.cc/article/66c68d1efd89780001106a58
Graph RAG 查詢可分 Local Search 與 Global Search
Local Search 跟目前的 RAG 差不多,僅透過近似查詢,而 Global Search 則是使用近似查詢加上 Graph 查詢找出有關聯的資料,讓查詢的結果更有整體性,須注意的是 Graph RAG 不管在 ETL 階段還是查詢花費的 Token 數量都很高,可以嘗試不同的 LLM,降低費用
除了引入 LangChain 上好用的查詢手法外,希望能融入更多 Spring 框架的特色,增強器就是不錯的例子,程式寫起來格外優雅,但 ETL 的 Transformer 用起來就很糟糕,除了函式一個包一個不易閱讀外,資料流方向也是由內而外,非常不直覺
在 Github 上看到有人在討論 Embedding 是否從 List<double> 改為 float[],Spring AI 的開發人員只會從程式的角度覺得 List 比較有彈性,卻不知道 Embedding 根本就不需要彈性,因為一次計算就是要寫這麼維度的數據進入向量資料庫,也不會中途修改一兩個內容
希望他們能有個真正理解 AI 生態的人來規劃整個框架
研究了 Spring AI 框架原始碼後,寫程式的思維開始不一樣,很多以前覺得困難的問題透過 AI 反而變得簡單,所以期許自己在鐵人賽後能完成 Java 版的 Graph RAG,其實這也是當初選 Neo4j 作為向量資料庫的原因
所以還請大家持續關注,鐵人賽結束了,凱文大叔的 AI 之旅才要開始
原本只想寫感想,最後還是把 Graph RAG 的概念加入,算是給 RAG 技術做一個結尾吧
凱文大叔使用 Java 開發程式超過 20 年,對於 Java 生態非常熟悉,曾使用反射機制開發 ETL 框架,對 Spring 背後的原理非常清楚,目前以 Spring Boot 作為後端開發框架,前端使用 React 搭配 Ant Design
下班之餘在 Amazing Talker 擔任程式語言講師,並獲得學員的一致好評
最近剛成立一個粉絲專頁-凱文大叔教你寫程式 歡迎大家多追蹤,我會不定期分享實用的知識以及程式開發技巧
想討論 Spring 的 Java 開發人員可以加入 FB 討論區 Spring Boot Developer Taiwan
我是凱文大叔,歡迎一起加入學習程式的行列

